Why Haskell became my favorite scripting language
Table of content
- A compiled language?
- Stack Script
- If it compiles, it works
- No ceremony
- Parser combinator libraries
- Code evaluation with Haskell-language-server
- Wrap up
I started learning Haskell a couple of years ago. My usual reason to learn a programming language is because I have a concrete use-case - a project I want to contribute to. With Haskell it was different. My primary motivation wasn’t a concrete use-case, but instead I thought studying the language would be worth it for the sake of learning. It does things different than other mainstream languages and I wanted to become familiar with concepts I hadn’t seen before.
Writing a couple of iterations of “Hello World” applications wasn’t going to get me far. Utilizing it in a project at work wasn’t an option - instead I started using it for my ad-hoc and utility scripts. Before, Python was my go-to language for such things, but Haskell ended up replacing it. In this article I will show why.
A compiled language? ¶
Haskell is as a compiled language, and you may wonder how on earth
you’d use it as a scripting language. The answer is that Haskell code
can run in an interpreted mode. The ghc package - the
package for the de-facto standard compiler for Haskell - has the
runhaskell program which uses this interpreter mode. You
can use it to execute Haskell files without intermediate compile
step.
If you put the following content in a file called foo.hs
you can execute it directly using ./foo.hs, assuming you
installed ghc:
#!/usr/bin/env runhaskell
main :: IO ()
main = putStrLn "Hello World"Interpreted mode is slower than compiling the code to an executable and running that, but for most scripting tasks it’s fast enough.
Stack Script ¶
runhaskell is nice, but if you do anything more involved
than Hello World you end up wanting to re-use existing
libraries. This is where stack script comes in. stack is a
build tool for Haskell and it provides the stack script
command, a more powerful alternative to runhaskell.
Let’s look at an example:
#!/usr/bin/env stack
{- stack script --resolver lts-17.9
--package process
-}
main :: IO ()
main = putStrLn "Hello World"The first line is the shebang that makes sure the script gets
executed using stack. The second line tells
stack that it should use the stack script
command. The --resolver flag needs some further
elaboration:
To build a program using stack it needs to know which
versions of the dependencies it should use. stack uses
package sets to aid with the decisions. A package set
is a pre-defined set of packages known to work together. The
--resolver flag declares the package set you want to use -
including the GHC version. You can think of using the
--resolver option as if nailing the versions of all the
dependencies, with the assurance that they work together. If you want to
learn more about that, take a look at Stackage.
The third line lists a dependency the script is going to use. You can add any number of dependencies this way:
#!/usr/bin/env stack
{- stack script --resolver lts-17.9
--package process
--package directory
--package network-uri
-}Another feature of stack script is the
--optimize flag: This will cause the script to compile
whenever it changes. This causes a slow down the first time a script
gets executed, but the next calls will be much faster because it will
use the cached, compiled version.
(In the JVM world there is jbang which does something similar. Overall I think this approach isn’t as widespread as it deserves to be and I once prototyped pipex to see how this could work in the Python world. (Don’t use that, it was only an experiment))
If it compiles, it works ¶
Or rather, if it type checks, it works. Dynamic typing proponents argue that the static type checks don’t offer a lot because you need to write functional tests anyway. I think the argument has some flaws, mostly because one advantage of type checks is to let you get away with writing fewer tests. Good use of types make it impossible to create illegal states. You can’t write unit tests to verify error cases if the compiler doesn’t let you create those error scenarios. And who writes tests for utility scripts?
But don’t take the “If it compiles, it works” mantra literally, there are plenty of bugs it won’t catch.
No ceremony ¶
This ties into the earlier two points. There is no tedious ceremony to bootstrap a project to get dependency management. The Haskell syntax is very succinct, Haskell has incredible type inference, together with the algebraic data type support it encourages using types even for ad-hoc scripts. In a language like Python you’d instead use dictionaries for everything - which may seem convenient but can mask bugs.
For example, I have a script that gets a list of emojis from the JSON file of the gemoji project and pipes them into bemenu:

I wrote the first version in Python. It was simple and worked, but it had a bug that I didn’t notice until the rewrite to Haskell.
In Haskell I defined a type, and derived a JSON de-serialization implementation:
data Emoji = Emoji
{ emoji :: String
, description :: String }
deriving (Show, Generic)
instance FromJSON EmojiYou can think of Emoji as a struct with two
fields, one for the emoji itself and one for its description. The
deriving and instance FromJSON are Haskell
features that let it derive a serialization implementation to parse
records like this:
emojis = eitherDecode emojiFileContents :: Either String EmojieitherDecode is a function from the Aeson library that
takes a ByteString and returns either an error message as
String, or the decoded value.
This returned an error message that told me some entries are missing
the description property. I had made an assumption about
the data that turned out to be wrong. Python let me get away with this
assumption but Haskell didn’t.
I decided that I don’t want emojis without description to show up, and changed the code to filter them out:
emojis = catMaybes <$> (eitherDecode emojiFileContents :: Either String [Maybe Emoji])Don’t worry if you’re not familiar with Haskell and find it difficult to understand these code snippets. My point is that types can help you find mistakes, and Haskell makes it easy to use types without introducing a lot of extra ceremony.
Parser combinator libraries ¶
Writing utility scripts often involves parsing some kind of output.
Many people resort to using regular expressions if they need to parse text. Sometimes they’re a perfect fit, but a regular expression can quickly reach a complexity threshold where you wish you had used something else.
One - in my opinion underutilized - alternative to regular expressions are parser combinator libraries. Parser combinator libraries allow you to write a parser in terms of individual small parse functions that you can then combine together to form the full parser. In some languages using them is a bit clunky, but the feature set of Haskell makes it convenient to use them.
Some examples of how this might look:
literal :: Parser Expr
literal = number <|> stringLiteral <|> objectLiteral <|> arrayLiteral
stringLiteral :: Parser Expr
stringLiteral = StringLiteral . T.pack <$> string
where
quote = char '\'' <|> char '"'
string = between quote quote (many (noneOf "\'\""))parseEntry :: Parser Entry
parseEntry = do
char '-'
char ' '
date <- parseDate
char ':'
char ' '
hours <- parseHours
char ' '
intervals <- between (char '(') (char ')') parseIntervals
pure $ Entry date hours intervals
where
parseIntervals = parseInterval `sepBy` char ','Code evaluation with Haskell-language-server ¶
Remember the point about testing?
The haskell-language-server supports evaluating code snippets in the documentation:
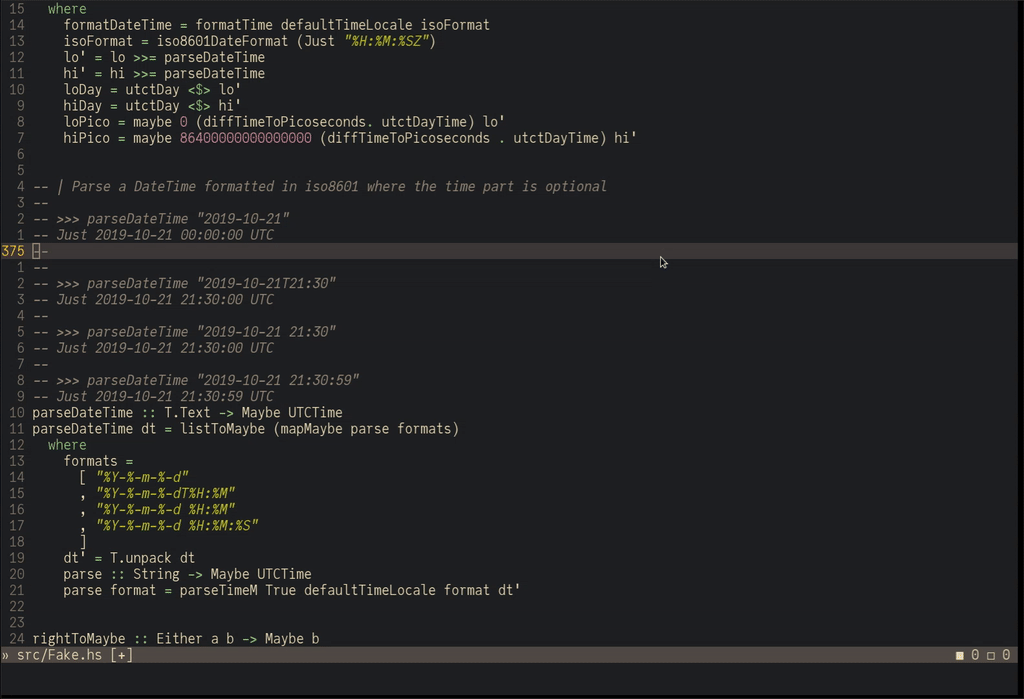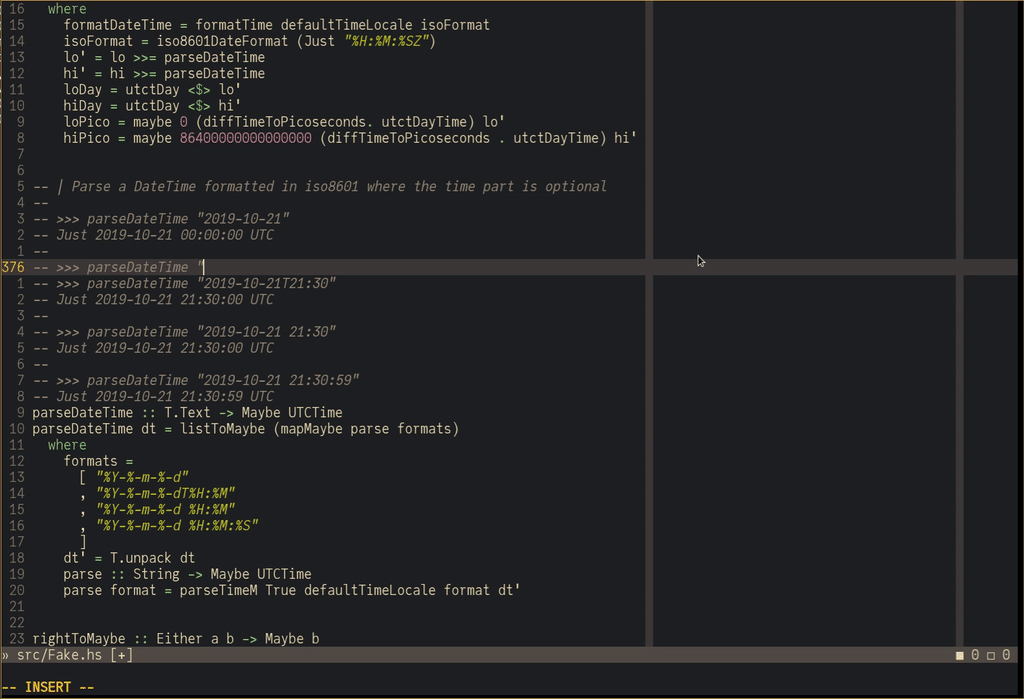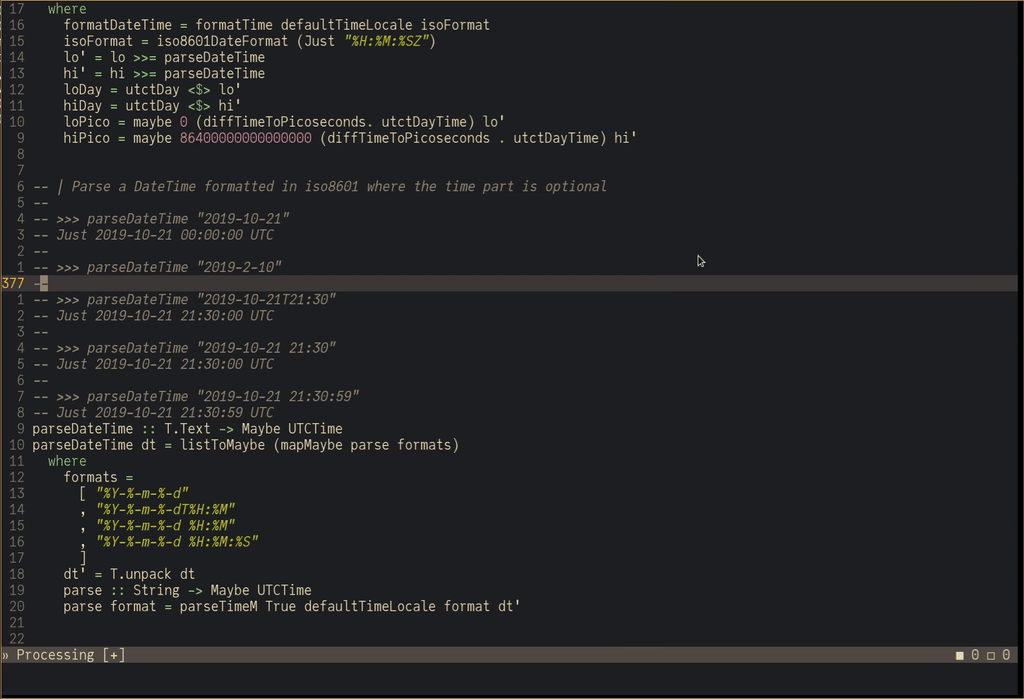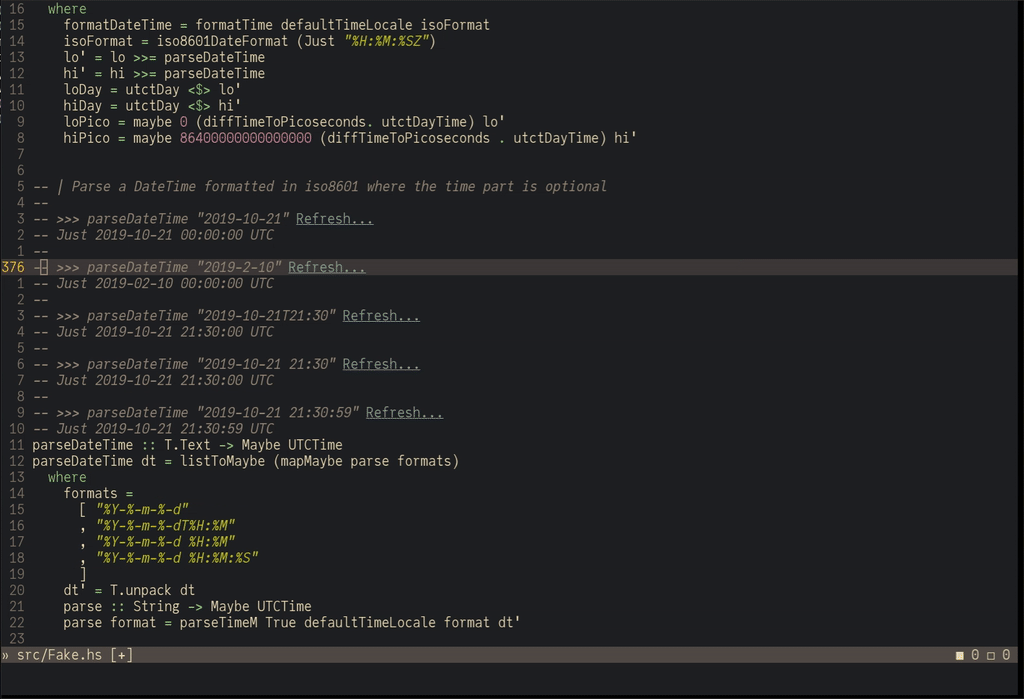
This is no replacement for a proper test suite, but it makes it ergonomic to quickly verify within a script if a function behaves as expected.
You can achieve something similar using an interactive REPL and sending code snippets to it, but I prefer this workflow.
Wrap up ¶
Although any single point here may not convince you, all put together turn Haskell into a powerful scripting language.
If you’re looking for a low risk way to learn the language, I can only recommend to start out using it for ad-hoc scripts or small utility programs.