Building SQL Auto Completion - Funday at CrateIO
At Crate we’ve recently introduced something that we call “Funday”. It is probably similar to what Google has been doing with their “20%” time. In this Post I will take a deep dive into the Crate core and explain how I used that time to build an auto completion mechanism for SQL statements.
Before I get into the nitty-gritty details let me first recap a bit why I think the Funday is a really cool concept.
At CrateIO we’re using Scrum to built our product and so far it has been working quite well. But as with everything in life and in particular software development there are always advantages and disadvantages. Scrum is no exception to that.
One thing that Scrum is doing is to get developers to focus on features that provide business value. There is almost no room to play around or try out new stuff. The creativity of the development team is restricted.
At Crate one way to let that creativity go lose was to have a hackathon. But events like that don’t happen all the time.
So recently we’ve introduced the concept of a “Funday”. Any developer can announce (before Planning 1) that he’ll have a “Funday” in the upcoming sprint - a day lasting from one Daily to the next where he can work on whatever he wants as long as it involves Crate in any form whatsoever. After the Funday the “result” - working or not - has to be presented to the team.
I’ve used my first Funday to build an SQL auto completion mechanism.
The motivation was simple: I was annoyed that each time I had to demo a
new feature I had to type whole column or table names. Hitting
TAB wouldn’t complete them.
The SQL parser in crate is built using ANTLR (3). I wanted to re-use the existing Grammer to avoid having to rebuild our SQL dialect from scratch. One of the requirements of an auto completion mechanism is that the parser has to be fault tolerant. Even if the syntax is invalid it still has to work in some way. A short research turned out that creating such a “fuzzy” parser isn’t something that ANTLR can do out of the box.
But what ANTLR actually does turns out to be enough anyway. ANTLR creates a Lexer and a Parser. The Lexer is a component that takes an arbitrary string as input and spits out tokens. Tokens are basically parts of that input string with an identifier attached to it that classifies that part.
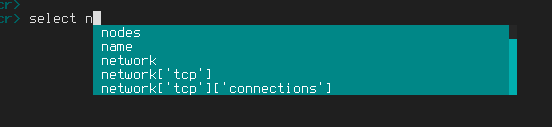
For example the following SQL statement:
SELECT n FROM tWould result in the following tokens:
SELECTas it is a keywordIDENTtoken withnas text - anIDENTbeing something pretty generic that mostly identifies columns but also tables and various other stuff.FROMtoken - again a keywordIDENTwithtas text
Usually a Parser takes these tokens and generates an abstract syntax tree. Using the same example the resulting syntax tree in Crate would look like (in a pseudo representation):
QuerySpecification(
From: [ Table(t) ],
Select: SelectItems: [ SelectItem(n) ]The parser is the strict component that will result in errors if the syntax is invalid. But the lexer is a little bit more tolerant.
So I settled to using the Lexer directly. My code takes a look at each token and creates some kind of context. In that context are information like “did I encounter FROM and a table”, “how many ident tokens have there been before the current one” and other stuff like that. All this information can then be used to reason about possible completions once the last token is encountered.
Let’s take a look at an example:
statement: seIn this case the lexer spits out an IDENT token. The
moment this token is encountered there is nothing else there. Which
means possible completions are all keywords that are valid at the start
of an SQL statement if they begin with se.
Another example would be:
select nIn this case select gets actually turned into a
SELECT token instead of an IDENT as it is
recognised. n is the next IDENT which at this
point can either be a schema name, a table name or a column name, so
everything starting with n can be returned.
In order to actually retrieve the values one or more SQL queries are executed. For example to retrieve the table names something like the following is invoked:
select distinct table_name from information_schema.tables where table_name like 'n%'Of course the whole logic gets more complex the more kinds of tokens are taken into account.
There might be better solutions to building an auto completion, but using this approach it was possible to get something to work within a day and although dumb the mechanism is actually already pretty useful.
After building the completion mechanism I hooked the functionality into the Crate infrastructure and exposed it as REST endpoint:
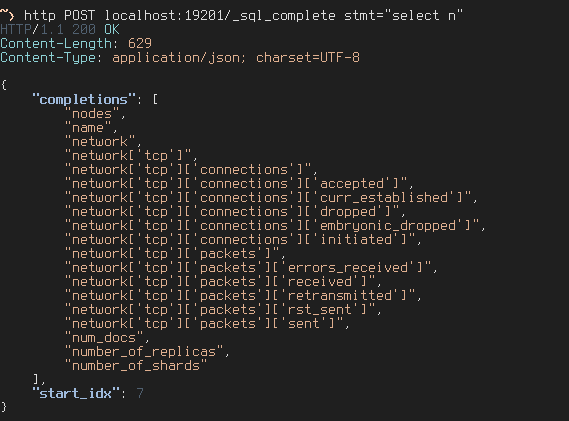
And tried to integrate it into Crash which is the command-line client that is bundled with crate. Crash is written in Python and uses the cmd module.
The cmd module has methods called
complete_<subcommand> which can be implemented in
order to provide auto completion. Unfortunately it turned out that the
interface of those methods is a bit problematic:
def complete_select(self, text, line, begidx, endidx):text being the text that cmd figured should
be completed and line being the complete line.
Problematic is that what cmd thinks should be
completed and what actually is completed are two things.
For example in Crate network['tcp'] is a valid column.
But cmd thinks that if the cursor is at
network[' everything after ' is already a new
word. In that case the value passed in the text parameter
is an empty string.
There is probably a way to get it to work properly by using begidx,
endidx and returned more information from the REST endpoint. But this
was a Funday: Instead of having a battle with cmd I decided
to try out the python-prompt-toolkit.
Which looks promising and turned out to work quite well: